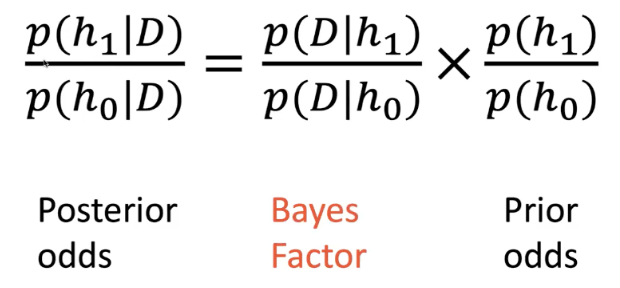Inference means making conclusions from data. We need probability because formal logic describes things as always or never true which is rarely true in real-life situations. Natural language is too subjective to describe the uncertainty in life, so we use math to describe uncertainty through probability.
An experiment is something repeatable. The probability space consists of the sample space, event space, and probability measure.
- Sample Space (Ω) is the set of all possible outcomes from one random experiment.
- The event space is the set of all events possible, while an event is a set of outcomes.
- A probability measure maps the event space to a number from 0 to 1.
A random variable is a function that maps the sample space to real numbers. Axioms are things we assume to be true.
Three Axioms of Probability:
-
Axiom 1: Probabilities are positive real numbers, greater than or equal to 0.
-
Axiom 2: The probability that an outcome is in the sample space (Omega) equals 1.
-
Axiom 3: For disjoint subsets, the probability of their union is the sum of their individual probabilities.
Probability Rules
-
Addition rule: The probability of a union b is p(a) + p(b) - p(a and b).
-
Multiplication rule: If events are independent, it's p(a) * p(b). If not independent, it's p(a) * p(b|a).
Conditional probability: p(b | a) is the probability of b given a, calculated as p(b intersection a) / p(a). The sample space shrinks to a, so of all probability of a, we need the part where b also happens.
Normal distribution occurs if 1) there are lots of events and 2) each event is independent of each other.
Moments characterize the shape of a distribution. Moments come from moment generating functions that converge (as some do not).
The moment generating function (MGF) of a random variable \(X\) is defined as:
\[M_X(t) = E[e^{tX}] = \int_{-\infty}^{\infty} e^{tx} f_X(x) dx\]
Example of a distribution that does not converge: The Cauchy distribution. It has undefined expected value and variance, with higher raw moments also undefined. It is characterized by fat tails. This becomes relevant when dealing with black swan events.
-
First (raw) moment: E[x], or the "balancing point". These are raw because they're centered on the origin.
-
Second (centralized) moment: Variance. These are centralised as they are calculated by subtracting the mean.
-
Third (centralized) moment: Cubed deviation. If equal, it's symmetric; otherwise, it's asymmetric.
-
Fourth moment (centralized): Kurtosis, which indicates heavy tails compared to a normal distribution. In a normal distribution, it drops off extremely and exponentially with increasing n.
There are 5+ moments, but these are the most common. For example, the Edgeworth series has hyper skew moment which is the 5th moment.